
As we close out 2024, the era of multimodal AI — systems that seamlessly integrate and process data from diverse sources like text, images, audio, and even video — has matured from a research curiosity into a cornerstone of modern enterprise solutions. This shift has been fueled, in part, by groundbreaking products such as Amazon’s newly launched Nova model suite and OpenAI’s Sora Turbo. Both represent a new generation of foundation models that process and fuse multiple data types, enabling capabilities that were once considered science fiction.
Multimodal AI provides a unified understanding of the world. It can, for instance, watch a product assembly line via video feed, read textual maintenance logs, listen to audio alerts, and then produce a comprehensive analysis to identify manufacturing defects in real-time. This holistic perspective transcends the boundaries imposed by single-modal systems, delivering richer insights and more nuanced decision-making capabilities.
From healthcare institutions like National Taiwan University Hospital (NTUH) leveraging multimodal AI to accelerate diagnostics, to multinational retailers using these models for inventory management and personalized marketing, the transformative potential of multimodal AI is profound. In financial services, advanced tools that see (surveillance), read (market reports), and listen (to real-time calls) can radically improve fraud detection and compliance.
In this blog post, we’ll explore the current state of multimodal AI, delve into the technical architectures and components necessary to build these systems, guide you through the practical steps to implement them at scale, and highlight their impact across industries. We’ll also look ahead to 2025 and beyond, examining how emerging trends and integrations — including Web3 and advanced agentic capabilities — promise to redefine how enterprises see, hear, and understand their data, customers, and operations.
Current State
2024 in Review:
The year 2024 saw multimodal AI transcend its nascent stage, moving from research labs into full production environments. Amazon Nova’s model suite stands at the forefront of this revolution. The Nova family — Micro, Lite, Pro, and soon Premier, along with Nova Canvas and Nova Reel — has ushered in a new standard for handling text, images, and video. Meanwhile, OpenAI’s Sora Turbo advanced text-to-video generation, providing faster and more accurate multimedia synthesis. Such capabilities have changed the competitive landscape, compelling companies like Meta, Google, and Stability AI to accelerate their own multimodal offerings.
Amazon Nova’s Multimodal Advantage:
Amazon’s Nova suite, integrated with Amazon Bedrock, offers a range of price-performance trade-offs suitable for different business needs. For example, Nova Lite provides ultra-low-cost multimodal processing, while Nova Pro delivers a balanced combination of accuracy, speed, and cost efficiency. These models allow enterprise developers to easily fine-tune them with their proprietary data, enabling domain-specific use cases like document processing, video analysis, and generative content creation. On top of these capabilities, Nova Reel can transform single images into dynamic video content, and Nova Canvas can create high-quality images for marketing and design tasks.
NTUH Healthcare Case Study:
National Taiwan University Hospital exemplifies the power of multimodal AI. By integrating text-based patient records, imaging data, and real-time voice inputs from clinicians, NTUH has developed large language models that summarize medical records, generate pathology reports, and even assist in telemedicine consultations. These multimodal solutions accelerate diagnosis, reduce administrative overhead, and enhance overall patient care. With the help of NVIDIA-powered supercomputers and fine-tuned multimodal large language models, NTUH’s healthcare applications now handle complex data streams — from unstructured text to radiological images and surgical training simulations — all within a unified system.
Market Metrics & Benchmarks:
Recent benchmarks highlight that enterprises adopting multimodal AI solutions have observed a 23-28% reduction in manual workloads and seen improvements in decision-making accuracy. The shift to multimodal frameworks has enabled a 3x increase in speed for tasks like image and document retrieval, a crucial advancement for industries handling large volumes of varied data. As generative AI models like Sora Turbo and Nova Pro become more accessible and integrated with enterprise stacks, these gains are expected to compound.
The current landscape shows clear momentum. The convergence of text, image, audio, and video processing in single foundational models has opened new doors, ignited competitive innovation, and paved the way for cost-effective, scalable solutions that meet complex business challenges.
Technical Components
Core Input Processing Systems
Multimodal AI solutions begin with robust input pipelines. Data can originate from images (JPEG, PNG), video streams (MP4), textual documents (PDF, DOCX), and audio files (WAV, MP3). Preprocessing steps standardize these inputs:
Image/Video Encoding:
Use vision transformers (ViT) or convolutional neural networks (CNNs) pre-trained on large-scale image datasets. For video, 3D convolutional models or temporal transformers extract spatiotemporal features. Amazon Nova Reel, for example, uses advanced video encoders optimized for low-latency inference on Amazon Bedrock.
Text Encoding:
Leverage large language models (LLMs) like Amazon Nova Micro (for cost-sensitive text-only tasks) or Nova Pro for more complex, multimodal tasks. Tokenization, sentence parsing, and embedding generation (e.g., using BERT or GPT-like architectures) transform raw text into vector representations.
Audio Processing:
For speech inputs, automatic speech recognition (ASR) models convert audio signals into text, which is then fed into LLMs. Alternatively, waveform encoders or spectrogram-based CNNs/transformers can be used for audio classification tasks.
Model Architecture Variations
After processing inputs, models must integrate different data modalities into a shared latent space. Key architectures include:
Two-Stream Architectures:
Separate encoders for each modality produce embeddings that are later fused. This approach is simpler but may miss intricate cross-modal relationships.
Single-Stream Multimodal Transformers:
Models that directly integrate modalities at the input layer, using cross-attention mechanisms to align text tokens with image/video patches or audio segments. Nova Pro and OpenAI Sora Turbo leverage such advanced transformer backbones to create unified embeddings, allowing the model to “see,” “hear,” and “read” simultaneously.
Late Fusion and Retrieval-Augmented Architectures:
Retrieval Augmented Generation (RAG) techniques fetch relevant data from external knowledge bases. For instance, Amazon Bedrock Knowledge Bases can ground model responses in enterprise data. By combining model outputs with external retrieval layers, the system ensures factual accuracy and domain relevance.
Output Generation and Formatting
Once integrated representations are formed, output generators produce text descriptions, generate images, or even create entire video sequences. Nova Canvas, for example, synthesizes images guided by text prompts. Sora Turbo can produce short video clips from narrative inputs. This multimodal output capability allows enterprises to create marketing content, summarize meeting videos, or provide visual explanations of complex data.
Python Code Example for Integration
Below is a simplified Python code snippet illustrating how to integrate a multimodal pipeline using a hypothetical API. Assume you have an LLM (text), a vision encoder (image), and an audio encoder (audio):
```python # Pseudocode for multimodal integration from multimodal_sdk import VisionEncoder, AudioEncoder, LLM, FusionModel
# Initialize encoders and models
vision_encoder = VisionEncoder(model_name=”nova-pro-vision”)
audio_encoder = AudioEncoder(model_name=”waveform-transformer”)
text_encoder = LLM(model_name=”nova-pro-text”)
fusion_model = FusionModel(model_name=”multimodal-fusion”)
# Load inputs
image_data = load_image(“product_shelf.jpg”)
audio_data = load_audio(“customer_feedback.wav”)
text_data = “Customer complaint: Missing product on shelf”
# Encode each modality
image_vec = vision_encoder.encode(image_data)
audio_vec = audio_encoder.encode(audio_data)
text_vec = text_encoder.encode(text_data)
# Fuse representations
multimodal_rep = fusion_model.integrate([image_vec, audio_vec, text_vec])
# Generate comprehensive response
response = text_encoder.generate(multimodal_rep, prompt=”Summarize the situation”)
print(response)
This code outlines a conceptual flow: image and audio encoders extract features, the LLM encodes textual data, and a fusion model integrates them. The output is a unified representation that can be prompted for tasks like summarization.
Security and Ethical Considerations
Multimodal AI systems process diverse datasets, including personal health records, financial statements, or user-generated content.
Security involves:
- Encryption of Data at Rest and In-Transit:
Use secure storage and TLS for data transmission. - Access Controls and Audit Logging:
Role-based access and strict audit trails ensure only authorized personnel interact with sensitive data. - Bias and Ethical Checks:
Models trained on diverse data sets must be regularly audited. Incorporate fairness metrics and debiasing techniques to prevent biased outputs.
Technical Diagrams
Diagram 1: Basic Multimodal AI Architecture
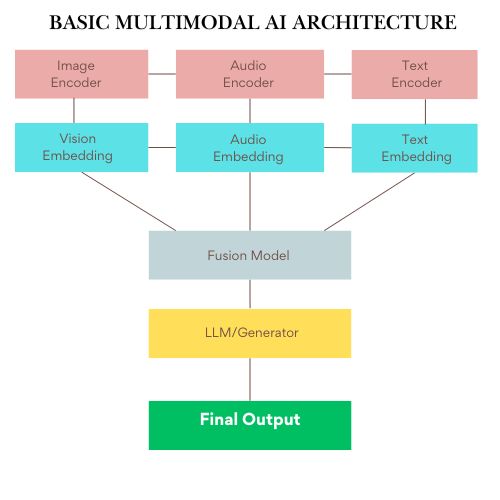
Diagram 2: Retrieval-Augmented Multimodal System
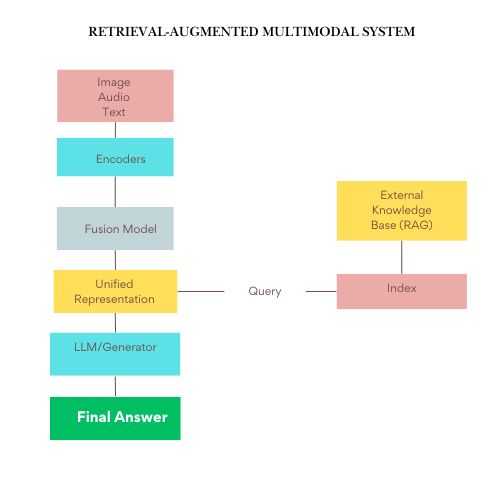
Implementation Guide
Technical Requirements
- Compute Infrastructure:
High-performance GPUs or TPUs are essential for training and inference. Cloud platforms like AWS with Amazon Inferentia and Trainium chips offer cost-effective, low-latency solutions. - Data Management:
Prepare a data lake for multimodal assets. Use AWS S3 or similar object storage for scalable data handling. Ensure metadata tagging to correlate different modalities (e.g., link product images to textual descriptions). - APIs and Frameworks:
Utilize Amazon Bedrock for seamless integration of Nova models. Frameworks like PyTorch, TensorFlow, and Hugging Face Transformers can accelerate model fine-tuning and deployment.
Scalability Considerations
- Horizontal Scaling:
Deploy multiple model instances behind load balancers. Use services like Amazon ECS or Kubernetes clusters to scale horizontally as request volumes grow. - Model Compression and Distillation:
Fine-tune teacher-student architectures to create smaller, faster models. Amazon Nova Premier can serve as a teacher model for distilling knowledge into efficient production-ready models. - Caching and Prompt Optimization:
Implement prompt caching strategies and intelligent routing to cut inference costs by up to 90%. Cache frequently used prompts and offload complex queries to more powerful models only when necessary.
Best Practices for Deployment
- Incremental Rollouts:
Start with a single-use case (e.g., automating customer support email + image-based product identification). Then expand as your team gains confidence. - Continuous Monitoring:
Track model performance with monitoring tools. Evaluate latency, throughput, and accuracy. Adjust compute resources and model variants as needed. - Retrieval-Augmented Generation (RAG):
Connect your multimodal models to internal databases. For instance, query a product database when generating descriptions for marketing videos. This ensures the output is both coherent and grounded in factual data.
System Architecture Diagram
Diagram 3: Enterprise Implementation Architecture
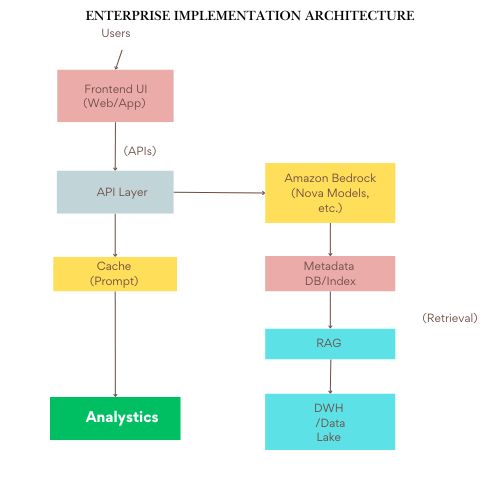
In this setup, the UI sends requests to an API layer that interfaces with Amazon Bedrock for inference. Prompts are cached to reduce cost, metadata databases and indexing systems support retrieval-based grounding, and analytics track system performance.
Security and Compliance
- Data Anonymization:
Remove sensitive identifiers from training sets. Use tokenization and encryption for personal data. - Regular Audits:
Periodically review model outputs for bias. Conduct penetration tests to ensure system security. - Compliance with Regulations:
In healthcare, ensure HIPAA compliance. In finance, meet KYC/AML standards. Leverage built-in compliance frameworks of AWS and third-party solutions.
Practical Steps
- Identify Priority Use Cases:
Start with tasks that offer quick wins, such as automating product descriptions or summarizing reports. - Select the Right Model:
For cost-sensitive and text-only workflows, Nova Micro works well. For advanced multimodal tasks, Nova Pro or Nova Lite might be ideal. - Fine-Tune and Test:
Fine-tune models on domain-specific datasets. Validate outputs with internal subject matter experts before going live. - Iterate and Improve:
Use user feedback and analytics to refine prompts, adjust model parameters, and introduce new modalities over time.
Industry Applications
Healthcare Use Cases
Hospitals and clinics integrate patient histories (text), medical images (X-rays, MRIs), and real-time audio from patient consultations into a unified diagnostic tool. LLMs generate clinical summaries, highlight anomalies in scans, and even propose follow-up tests. NTUH’s multimodal deployment improved report generation, streamlined telemedicine sessions, and enhanced care quality.
Pharmaceutical firms leverage multimodal AI to accelerate drug discovery by integrating molecular imagery, chemical compound data, and scientific literature. This speeds up R&D cycles and reduces time-to-market.
Enterprise Implementation Examples
Retail and E-Commerce:
Retailers employ cameras to monitor shelves, reading product labels and correlating inventory data with sales records. These systems detect stockouts and compliance issues in planograms, reducing shrinkage and improving the shopper experience. One retailer reported a 13% increase in sales after using multimodal AI to optimize product placement and respond faster to customer feedback.
Financial Services:
Banks use multimodal AI to fuse transaction logs, voice call transcripts, and regulatory documents. The result is better fraud detection, compliance checks, and customer support. For example, a financial institution integrated Nova Pro with RAG-based retrieval to confirm the authenticity of documents, improving onboarding speed while maintaining stringent compliance.
Manufacturing:
Multimodal sensors on factory floors (video feeds, audio alarms, textual maintenance logs) feed into a single AI system to detect defects, predict machine failures, and ensure safety compliance. This reduces downtime by up to 21% and improves overall equipment effectiveness.
Creative Industry Applications
Media and advertising agencies can generate personalized, culturally relevant campaigns by blending text-based market analyses, image mood boards, and audience reaction videos. Advanced models like Sora Turbo create video snippets that align perfectly with brand messaging. This helps marketers iterate campaigns faster, predict audience engagement, and optimize spend.
Film and gaming studios integrate multimodal AI to enhance production pipelines. AI can read scripts, analyze storyboards, evaluate motion capture data, and generate video assets. As a result, creative teams move from concept to final product more efficiently, supported by real-time AI-driven suggestions.
Real Performance Metrics
- Healthcare: A 20% reduction in time for generating patient summaries and a 15% improvement in diagnostic accuracy due to integrated insights.
- Retail: A 3x faster response to in-store conditions (e.g., stockouts) and a 28% reduction in manual workload for inventory checks.
- Manufacturing: Downtime reduction of up to 16% by detecting machine anomalies through combined visual and audio analysis.
From the factory floor to the doctor’s office, multimodal AI revolutionizes how industries operate. As models become cheaper and easier to deploy, these gains will spread to even more sectors.
Future Outlook
2025 Innovation Predictions
By 2025, we expect even tighter integration of multimodal AI within business processes. Gartner predicts that by 2027, 40% of generative AI solutions will be multimodal. Models will become more energy-efficient, scaling seamlessly to handle billions of parameters without prohibitive costs. Agentic AI — where autonomous “agents” make decisions to achieve user-defined goals — will evolve from experimental demos to production-ready solutions, orchestrating complex workflows with minimal human intervention.
Emerging Trends
- Context-Aware Agents:
Next-generation agents will remember historical interactions and adapt on-the-fly. They’ll handle tasks like supply chain optimization by considering data from multiple sensors, market trends, and even global events. - Integration with Web3:
Decentralized storage and blockchain technologies could provide secure, tamper-proof records for multimodal AI. This ensures data authenticity and addresses regulatory requirements around data provenance. - Domain-Specific Fine-Tuning:
Industry-tailored multimodal models (e.g., finance-focused LLMs integrated with trade analytics) will become standard. This reduces time-to-value for enterprises and delivers better domain accuracy.
Security and Ethical Horizons
With more data types comes greater responsibility. In 2025, enterprises will invest heavily in governance frameworks and AI governance platforms to manage data integrity and privacy. This includes advanced watermarking for generated videos (like Sora Turbo’s C2PA metadata) and robust compliance layers to meet expanding global regulations.
Future Technical Directions
Expect more model compression techniques and hybrid computing approaches to handle massive multimodal workloads efficiently. Innovations in postquantum cryptography will secure sensitive data, and advanced chip designs (like AWS Trainium) will make large-scale multimodal inference more cost-effective.
As models become more capable, they will not only interpret diverse modalities but also reason about their relationships. Systems will move beyond just “seeing” and “hearing” to truly “understanding,” blending logic, context, and multimodal cues into coherent, reliable outputs.
Conclusion
Multimodal AI integration marks a pivotal shift in how businesses process and leverage information. With Amazon Nova’s robust suite of models, OpenAI’s Sora Turbo pushing boundaries in text-to-video synthesis, and innovative deployments in healthcare, finance, retail, and beyond, the future has never been more exciting. As we head into 2025, decision-makers who invest in multimodal AI will find themselves better positioned to meet evolving challenges, seize new market opportunities, and reshape their industries.
For organizations ready to embark on this journey, the roadmap is clear: start small, ensure robust security and compliance, leverage proven platforms, and refine continuously. The era of AI that sees, hears, and truly understands is here — it’s time to embrace it.
{kind=link}